
Tin (Kevin) Nguyen
I am a PhD student in Computer Science at
Auburn University, working with
Prof. Anh Totti Nguyen and Prof. Chirag Agarwal at UVA.
My research focuses on agentic AI, AI Safety and Security, and HCI.
Email:
ngthanhtinqn@gmail.com or ttn0011@auburn.edu
Currently, I am working as a Research Assistant @ Aikyam Lab, University of Virginia — May–Aug 2026
Publications my favorites () | others ()


TMLR, 2026
Also accepted at NeurIPS 2025 Workshop Multimodal Algorithmic Reasoning (MAR) —
Oral
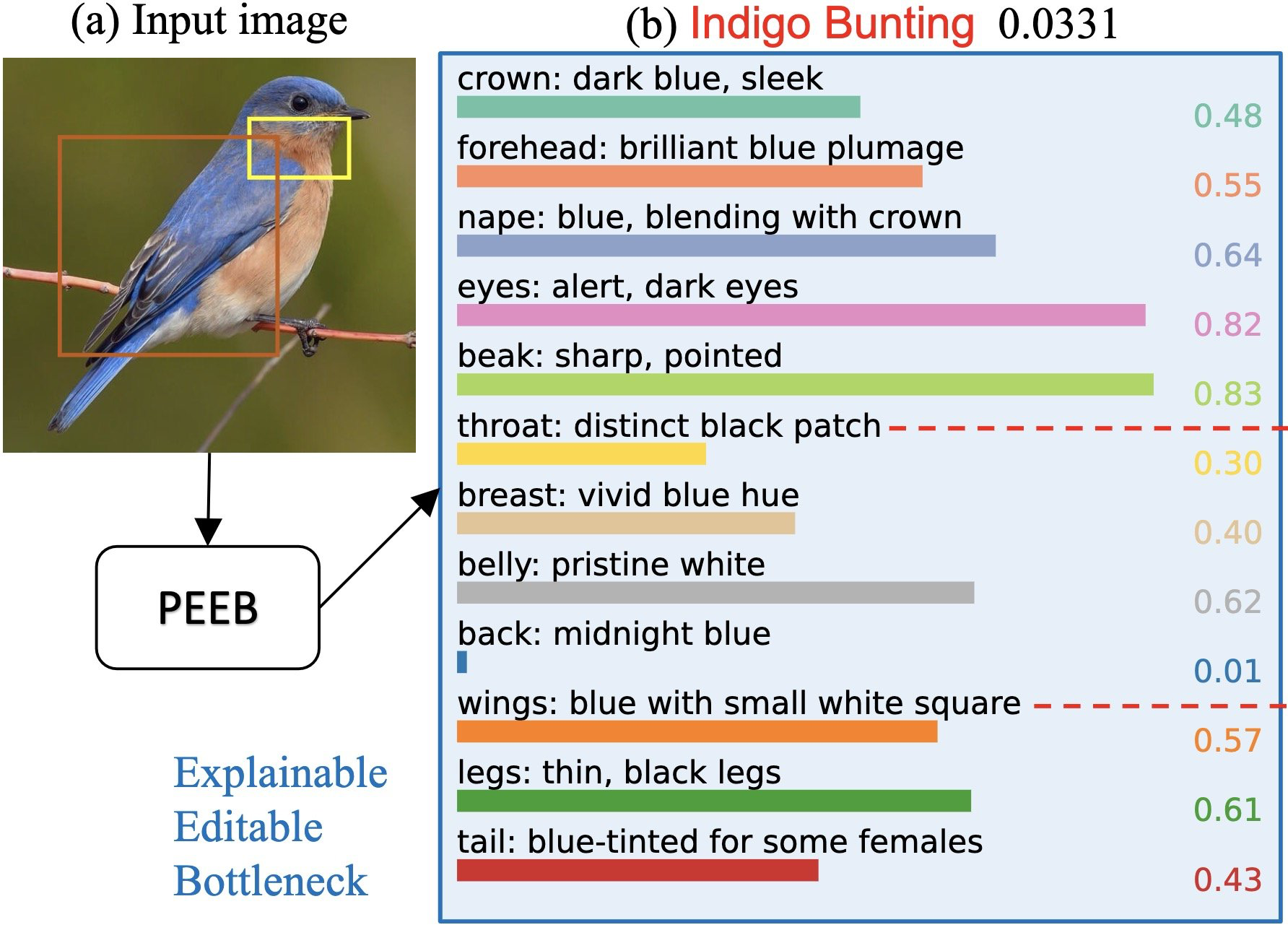
Knowledge-based Systems (KBS), Jul 4, 2023
ICML, 2026
I contributed two tasks evaluating object counting and physical reasoning capabilities of video-language models.
Academic Service
- Reviewer for ARR Rolling Review (ACL, EMNLP, NAACL), UIST, HAI, Knowledge-based Systems
- Teaching Assistant at K-6 AI Club at Auburn University